1. KCP
按KCP的README,这协议并不是设计来跑大流量的:
TCP是为流量设计的(每秒内可以传输多少KB的数据),讲究的是充分利用带宽。而 KCP是为流速设计的(单个数据包从一端发送到一端需要多少时间),以10%-20%带宽浪费的代价换取了比 TCP快30%-40%的传输速度。
从它的技术特性,你也可以得知这协议相对TCP的重点改进是在重传上,而不是拥塞控制。那它为什么快(某些情况下)呢?一方面,它重传机制的改进,丢包后可以更早重传,对方更早收到补发的包,更早能把数据递交给应用层,缓冲区的释放更快,发送方也能更早继续发送后续的数据;另一方面,它技术特性里面有个“非退让流控”,名字听起来略微高端大气上档次,其实通俗点来讲就是没有拥塞控制。简单来说,就是拥塞窗口大小不会因丢包率发生变化,也不需要经历TCP的慢启动阶段,KCP会尽可能地帮你把自己的发送窗口或者对方的接收窗口塞满。还有就是,大概很多人用的都不是纯skywind3000实现的kcp,而是xtaci的kcptun,这实现默认启用了FEC,每十个包发送三个冗余,补偿了丢包。
2. QUIC
应该有不少人听过QUIC,那KCP跟QUIC相比,哪个好呢?其实QUIC的比纯KCP丰富得多完整得多,还真的不太好对比,这里就拿QUIC跟xtaci的KCP实现进行对比吧。这里你可以暂时简单地把QUIC看作xtaci的KCP+BBR,所以“非退让流控”变成了“BBR拥塞控制”。有拥塞控制的好处是窗口可以自动调整,例如像HTTP这种公开的网络服务,服务器预先是不了解客户端的带宽、网络拥塞状况是如何的,因此需要一个拥塞控制算法,经历慢启动,根据丢包动态地调整窗口。如果说你很了解两个host之间的网络状况,或者说想保证两点间的传输质量,这种情况拥塞控制就有点多余了,“非退让流控”倒是能让你得到更好的体验。所以哪个更好,还得看场景。
QUIC的特性有一项是“无队头阻塞的多路复用(Multiplexing without head-of-line blocking)”,xtaci的kcp也有实现多路复用,但并不能避免队头阻塞,注意这里所说的队头阻塞并不是kcptun开发小记所提到缓冲区耗尽导致的那种阻塞,而是因KCP无法感知上层的多路复用所导致的队头阻塞。例如A向B发送了编号为0-9的十个数据包,但是其中1丢了,即使2-9中的数据跟1是毫不相关的,2-9携带的数据也因为1的丢失而无法及时递交给应用层。这也是为什么QUIC要使用UDP,因为TCP的机制就决定了一定会发生队头阻塞,HTTP/2在TCP上实现了多路复用,解决了HTTP/1.1的队头阻塞问题,但解决不了TCP的,所以这也是为什么会有HTTP/3,而且还要用QUIC。目前KCP多路复用的实现仅类似于HTTP/1.1到HTTP/2。
此外还有连接迁移(Connection Migration),xtaci实现的kcp是不支持此特性的,也就是说,如果客户端的IP和端口发生了变化,那么先前构建的KCP连接就失效了。
3. KCP-GO的INPUT/OUTPUT
3.1. OUTPUT流程

应用层发出数据调用的是WriteBuffers(),WriteBuffers()把一大份数据拆分成一份份mss大小的;KCP.Send()把mss大小的数据存入队列;KCP.flush()主要负责构建数据包,还有重传的判断;UDPSession.output()负责加密、CRC32校验以及FEC;到uncork()和tx(),就是调用操作系统的API发出UDP数据包了。
其中的update()会周期性调用,周期通过参数interval指定。
3.2. INPUT流程

monitor()和UDPSession.readLoop()都是通过系统调用接收UDP包,区别是monitor()用于server模式,readLoop()用于client模式。Listener.packetInput()与UDPSession.packetInput()负责解密、CRC32校验。UDPSession.kcpInput()负责FEC。KCP.Input()对数据包的包头进行解析,根据其中的CMD,做出对应的处理。
4. 重传
重传机制的实现在KCP.flush()中,分别有fast retransmit、early retransmit以及RTO retransmit。
KCP-GO通过KCP结构体中的名为“snd_buf”的数组对待发以及已发出还未被ACK的segment进行跟踪,以实现重传。这个数组的类型是名为segment的结构体,segment中的ts、rto、resendts以及fastack与重传有关。
Segment跟数据包有什么关系呢?每个segment都拥有一个完整的KCP header,header中有这个segment所携带的payload的长度,因此一个数据包中,可以有多个segment,只要不超过MTU。ACK就是一个包中携带多个segment的例子:
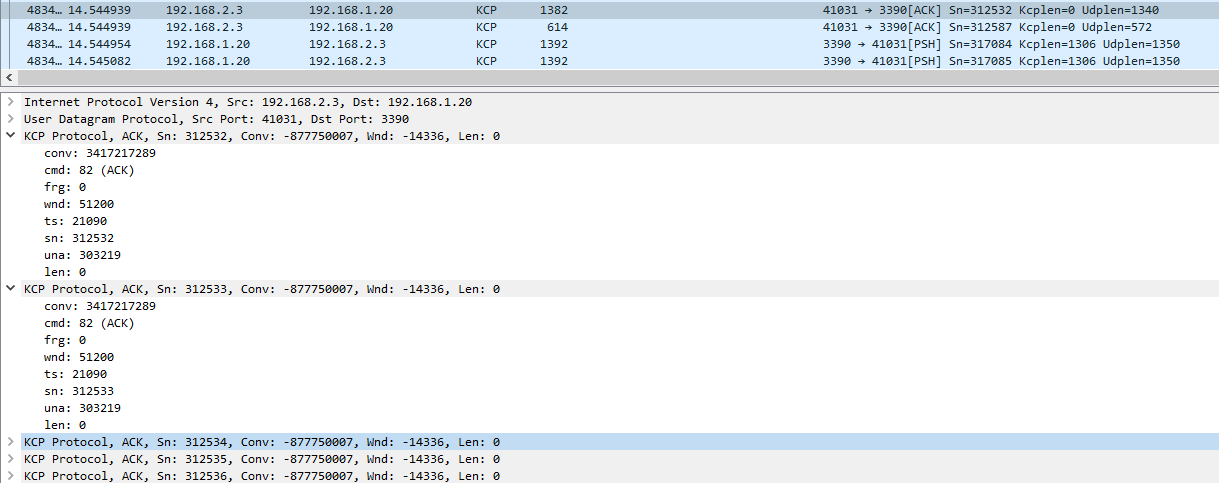
4.1. RTO Retransmit
当一个push segment(带数据)需要发出时,会记录当前的RTO,并且通过resendts记录超时的时间:
|
1 2 3 4 |
... segment.rto = kcp.rx_rto // 当前的RTO segment.resendts = current + segment.rto // 超时时间 = 当前时间 + RTO ... |
这里你可以看到,这个resendts就很准地定在了一个RTO,而且是当前的RTO,其实这里会导致一些问题,文后再提。
遍历snd_buf中的segment时,就通过这个resendts来判断是否需要重传:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... } else if _itimediff(current, segment.resendts) >= 0 { // RTO needsend = true // 需要发送 // 下面的跟退让相关 if kcp.nodelay == 0 { segment.rto += kcp.rx_rto } else { segment.rto += kcp.rx_rto / 2 } segment.fastack = 0 // 避免再次快速重传 // 重新计算下一次需要重传的时间 segment.resendts = current + segment.rto ... } ... |
上面对segment.rto的计算,是重传的退让,其中对kcp.nodelay的判断,对应KCP特性中的“RTO翻倍vs不翻倍”,除以2那个是1.5倍。
KCP-GO的RTO并没有应用指数退让,每次重传RTO的增量只是一个(或者0.5个)RTO,这是跟skywind3000/kcp不一样的地方。
4.2. Fast Retransmit
即KCP特性中的快速重传,通过判断segnemt->fastack的值是否大于设定被跳过的次数,决定是否需要进行fast retransmit。
发出segment时,会在segment的ts中记录当前的时间:
|
1 2 3 4 5 6 7 8 |
... if needsend { current = currentMs() ... segment.ts = current ... } ... |
对方响应ack时,会把对应包的ts也带上,这个一方面用于计算RTT,另一方面,收到不是对应这个segment的ack时,可用于判断这个ack,是否应该在这个segment在应该到达对方的时间点后响应的,只要ack中的ts大于等于这个segment的ts,就可以肯定这个ack应该是在这个segment到达后(理论上应该到达)响应的,因为既然同时以及后来发segment都被ack了,那这个segment也应该到了,这时就可以给这个segment ack被跳过次数的计数器+1:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
func (kcp *KCP) parse_fastack(sn, ts uint32) { ... for k := range kcp.snd_buf { seg := &kcp.snd_buf[k] if ... { ... } else if sn != seg.sn && _itimediff(seg.ts, ts) <= 0 { seg.fastack++ } } } |
上面的_itimediff(seg.ts, ts) <= 0,就是对比这个ack的ts,是否大于等于segment中的ts,是的话,被跳过的次数+1。
flush()中遍历snd_buf时,就通过比较fastack是否大于设定的值,以决定是否要应用fast retransmit:
|
1 2 3 4 5 6 7 8 9 |
... } else if segment.fastack >= resent { // fast retransmit needsend = true // 需要发送 segment.fastack = 0 segment.rto = kcp.rx_rto segment.resendts = current + segment.rto ... } else if ... ... |
4.3. Early Retransmit
这个是KCP中没有提到的,先来看看应用这个机制的判定条件:
|
1 2 3 4 5 6 |
... } else if segment.fastack > 0 && newSegsCount == 0 { // early retransmit needsend = true ... } else if ... { ... |
这里又出现了fast retransmit的fastack,条件是大于0,也就是只要被跳过;那newSegsCount又是哪来的呢?:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
... newSegsCount := 0 for k := range kcp.snd_queue { if _itimediff(kcp.snd_nxt, kcp.snd_una+cwnd) >= 0 { break } newseg := kcp.snd_queue[k] ... // 分配编号 kcp.snd_buf = append(kcp.snd_buf, newseg) ... newSegsCount++ } ... |
snd_queue是在UDPSession.WriteBuffers()中对数据拆分后,调用KCP.Send()存入的,这里这个for循环的任务是给snd_queue中的每份segment分配sn,也就是编号,然后存入到snd_buf中;cwnd是拥塞窗口,cwnd = min(发送方的发送窗口, 接收方的接收窗口)。
newSegsCount要为0的话,要么就是snd_queue为空,要么就是刚进循环,就被“_itimediff(kcp.snd_nxt, kcp.snd_una+cwnd) >= 0”这个判定条件给break了。
kcp.snd_nxt是要下一个要发出的segment的编号,kcp.snd_una是发送方滑动窗口的左边沿,也就是已发出或者将要发出的数据包中,还未被确认的且编号最小的那一个(注意这里的滑动窗口是不受选择性重传的ACK影响的,窗口仅会在对方响应的una发生变化后滑动,见KCP.parse_una())。kcp.snd_una+cwnd就是滑动窗口的右边沿。所以,这个条件,判断的就是要发出的segment的编号,是否已经超过了滑动窗口的右边沿;换句话说,这个比较为true的条件就是:发出的segment已经把窗口塞满了。
所以如果snd_queue为空,或者窗口已满的情况下,就有可能触发重传,重传那些有被ack跳过的segment。那这个重传机制的意义在哪呢?
窗口的滑动是仅在对方响应的una更新后发生,una的值代表的是,una前的编号的segment,都已经收到了。理想情况下,窗口应该是持续向右滑动的,这时窗口停止滑动,导致segment把窗口塞满,而且还有segment被ack跳过,那完全可以判定为丢包了,因为丢包会阻止una的更新。
4.4. 关于重传的一些备注
KCP的特性中有选择性重传,上面没有专门提到这个机制,其实上面的三个重传机制的实现都是选择性重传的,因为他们都是对单个segment进行跟踪。
KCP的最小RTO定在100ms,所以如果两个host之间的RTT小于100ms,生效的重传机制基本不会是RTO那个。
5. KCP-GO的四个参数
用KCPTUN的可能不了解这四个参数,因为这四个参数是隐藏参数,一般来说用户传的是normal、fast、fast2和fast3。
四个参数分别是no delay,interval,resend和no congestion。
no delay是RTO的退让,在KCP-GO中,未启用增加一个RTO,启用后增加0.5个;interval是调用UDPSession.update()的周期,单位是ms;resend是fast retransmit的参数,即segment被ack跳过多少次后,应该视为丢包并重传;no congestion即是否禁用拥塞控制,对应KCP特性中的“非退让流控”,千万别设为0,不然你不如考虑TCP+BBR吧。
四种模式,有何区别呢:
|
1 2 3 4 5 6 7 8 9 10 |
switch config.Mode { case "normal": config.NoDelay, config.Interval, config.Resend, config.NoCongestion = 0, 40, 2, 1 case "fast": config.NoDelay, config.Interval, config.Resend, config.NoCongestion = 0, 30, 2, 1 case "fast2": config.NoDelay, config.Interval, config.Resend, config.NoCongestion = 1, 20, 2, 1 case "fast3": config.NoDelay, config.Interval, config.Resend, config.NoCongestion = 1, 10, 2, 1 } |
最大的区别大概就是interval了,这个参数是调用UDPSession.update()的周期,update()调用的是KCP.flush()。
KCP.flush()负责响应ack,从snd_queue取出segment分配sn并发出segment,跟踪丢失的segment,并重传。默认情况下,调用wirte()向对方发送数据并不会等到下一个update()调用才发出,前面所提供的流程图,write()是有指向flush()的。ACK则默认会延迟到每个update()的调用才发出,除非你启用了ack nodelay(一般来说不建议启用)。所以interval影响的是跟踪丢包以及响应ack的周期。
对于发送方来说,如果持续有数据发送,这个interval的影响不是很大。不过如果接收方是重收轻发的,那这个interval对发送方的丢包检测影响就很大。因为发送方对RTT的计算、以及丢包重传机制的应用都是通过ack实现的,interval越小,ack响应越快,那发送方就越早能发现丢包,越早重传。
6. 带宽利用率的提升
文章开头提到这协议不是设计来跑大流量的,实践过程中发现,跑大流量,的确是有点问题。
多跑流量这个有很多讨论,其实这个是有办法避免。多跑流量的原因,你能看到的可能有窗口设置不合理、内核socket缓冲区不够大,客户端处理不过来、还有FEC。其实这几个原因都不是关键。
先来看看这个多跑流量的问题有多严重。
6.1. 多跑了多少流量?
A和B之间是142ms RTT,千兆带宽,先用iperf3测测A以百兆速率向B发送数据的UDP丢包率:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
root@A:~# iperf3 -u -b 100M -c B Connecting to host B, port 5201 [ 5] local A port 33404 connected to B port 5201 [ ID] Interval Transfer Bitrate Total Datagrams [ 5] 0.00-1.00 sec 11.9 MBytes 99.9 Mbits/sec 8627 [ 5] 1.00-2.00 sec 11.9 MBytes 100 Mbits/sec 8633 [ 5] 2.00-3.00 sec 11.9 MBytes 100 Mbits/sec 8633 [ 5] 3.00-4.00 sec 11.9 MBytes 100 Mbits/sec 8632 [ 5] 4.00-5.00 sec 11.9 MBytes 100 Mbits/sec 8632 [ 5] 5.00-6.00 sec 11.9 MBytes 100 Mbits/sec 8633 [ 5] 6.00-7.00 sec 11.9 MBytes 100 Mbits/sec 8633 [ 5] 7.00-8.00 sec 11.9 MBytes 100 Mbits/sec 8632 [ 5] 8.00-9.00 sec 11.9 MBytes 100 Mbits/sec 8633 [ 5] 9.00-10.00 sec 11.9 MBytes 100 Mbits/sec 8633 - - - - - - - - - - - - - - - - - - - - - - - - - [ ID] Interval Transfer Bitrate Jitter Lost/Total Datagrams [ 5] 0.00-10.00 sec 119 MBytes 100 Mbits/sec 0.000 ms 0/86321 (0%) sender [ 5] 0.00-10.22 sec 119 MBytes 97.8 Mbits/sec 0.023 ms 0/86295 (0%) receiver |
网络质量非常优秀,没有丢包,再来看看KCP-GO,从A发送1GB数据到B,重传了多少,关闭nodelay,关闭FEC,关闭fast retransmit:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
root@A:~# server_linux_amd64 \ --target 127.0.0.1:80 \ --listen 0.0.0.0:8080 \ --mode manual --nodelay 0 --interval 10 --resend 0 --nc 1 \ --nocomp \ --crypt none \ --datashard 0 --parityshard 0 \ --sndwnd 2048 --rcvwnd 2048 \ --sockbuf 33554432--smuxbuf 33554432 \ --key key \ --dscp 46 2021/03/10 15:49:29 version: 20210103 ... 2021/03/10 15:51:01 KCP SNMP:&{BytesSent:1075839321 BytesReceived:199 MaxConn:1 ActiveOpens:0 PassiveOpens:1 CurrEstab:1 InErrs:0 InCsumErrors:0 KCPInErrors:0 InPkts:7691 OutPkts:1161865 InSegs:7699 OutSegs:1161866 InBytes:184975 OutBytes:1242733109 RetransSegs:113270 FastRetransSegs:0 EarlyRetransSegs:0 LostSegs:113270 RepeatSegs:0 FECRecovered:0 FECErrs:0 FECParityShards:0 FECShortShards:0} |
OutSegs:1161866,RetransSegs:113270,LostSegs:113270,发出了116万个segment,重传了11万+。
那到底是不是真的丢了那么多个segment呢?看看B的统计数据:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
root@B:~# client_linux_amd64 \ --remoteaddr A:8080 \ --localaddr :33891 \ --mode manual --nodelay 0 --interval 10 --resend 0 --nc 1 \ --nocomp \ --crypt none \ --datashard 0 --parityshard 0 \ --sndwnd 2048 --rcvwnd 2048 \ --sockbuf 33554432 --smuxbuf 33554432 \ --key key \ --dscp 46 2021/03/10 15:49:32 version: 20210103 ... 2021/03/10 15:50:57 KCP SNMP:&{BytesSent:199 BytesReceived:1075839321 MaxConn:1 ActiveOpens:1 PassiveOpens:0 CurrEstab:1 InErrs:0 InCsumErrors:0 KCPInErrors:0 InPkts:1161865 OutPkts:7691 InSegs:1161866 OutSegs:7699 InBytes:1219495809 OutBytes:338795 RetransSegs:0 FastRetransSegs:0 EarlyRetransSegs:0 LostSegs:0 RepeatSegs:113270 FECRecovered:0 FECErrs:0 FECParityShards:0 FECShortShards:0} |
RepeatSegs:113270,跟A统计的重传数一致,也就是说,这些重传的,一个都没丢,全都是重复发送,有近十分之一的流量是多跑的。如果跑的带宽更大,还启用了fast retransmit的话,这个repeat数将会更高。
如果让KCP-GO输出RTO、重传的记录以及ack的时间,你会发现很多类似这样的记录:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
... 2021/03/09 11:30:50 RTO: 193 ... 2021/03/09 11:30:50 RTO: 193 ... 2021/03/09 11:30:50 RTO Retransmit sn: 850928, ts: 46123, resendts: 46303 at 46306 ... 2021/03/09 11:30:50 ACK sn: 850928, una: 836189, ts: 46123 at 46321 ... 2021/03/09 11:30:50 RTO: 220 ... 2021/03/09 11:30:50 RTO: 221 ... 2021/03/09 11:30:50 RTO: 217 ... |
850928这个segment在46306ms重传了,但是在15ms后,也就是46321ms收到了ack。收到这个850928的ack时,计算出的RTO也从193ms上升到了220ms。如果你还开了fast retransmit,最严重的情况,就是fast retransmit一次,然后RTO也retransmit一次。
前面介绍重传,有提到segment resendts的计算是当前的时间+当前计算出的RTO,会导致一些问题。影响RTT的因素有很多,除了当前的网络状况,还有双方的CPU负载、调度等问题,这些因素每一刻都在发生变化,特别是KCP属于用户空间的程序,CPU负载和调度等问题对这个影响更大。而RTT越高,在路上的ack就越多,例如A和B之间是142ms的RTT,参数设定的interval是10ms,那从一个segment的发出,到对应这个segment的ack,这期间RTO能更新14次以上!此外,我们永远也无法预先知道这个segment的发出,到收到响应,需要多少时间。
一方面,可以改进计算RTT的算法,KCP的RTT算法并没有什么问题,不过可能因为KCP是用户空间的,太容易受影响,变化太突然,采用的算法不能很好地应付这种情况。另一方面,我们可以不要用固定的resendts去与当前的时间比较,而是用segment发出的时间+当前最新的RTO与当前时间进行比较决定是否需要重传。此外,还可以给RTO应用一个退让;在Linux Kernel中,第一次重传的时间其实不是定在当前时间+一个RTO,而是对初始RTO应用了一个系数为2的退让,例如计算出的RTO是200ms,那第一次重传的时间是当前时间+2*RTO,也就是400ms后,而不是200ms:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
/* If stream is thin, use linear timeouts. Since 'icsk_backoff' is * used to reset timer, set to 0. Recalculate 'icsk_rto' as this * might be increased if the stream oscillates between thin and thick, * thus the old value might already be too high compared to the value * set by 'tcp_set_rto' in tcp_input.c which resets the rto without * backoff. Limit to TCP_THIN_LINEAR_RETRIES before initiating * exponential backoff behaviour to avoid continue hammering * linear-timeout retransmissions into a black hole */ if (sk->sk_state == TCP_ESTABLISHED && (tp->thin_lto || net->ipv4.sysctl_tcp_thin_linear_timeouts) && tcp_stream_is_thin(tp) && icsk->icsk_retransmits <= TCP_THIN_LINEAR_RETRIES) { icsk->icsk_backoff = 0; icsk->icsk_rto = min(__tcp_set_rto(tp), TCP_RTO_MAX); } else { /* Use normal (exponential) backoff */ icsk->icsk_rto = min(icsk->icsk_rto << 1, TCP_RTO_MAX); // RTO * 2 } |
当然,也不是所有情况都应用这种初始退让,上面的代码中,还有个thin stream的判断,这个功能默认是没启用的,大概就是,如果发出去还没被ack的包少于4个,就在一个RTO后立刻重传。
对算法进行改进这个可能有点挑战;对resendts的改进有效果,但不算很大;实测还是对KCP的RTO应用一个退让简单,而且效果也是非常好,当然也不需要像TCP那样两倍这么夸张,我这里选了1.125倍,重传量为1756,对比原先的11万,少了99.9%:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
root@A:~# server_linux_amd64_new \ --target 127.0.0.1:80 \ --listen 0.0.0.0:8080 \ --mode manual --nodelay 0 --interval 10 --resend 0 --nc 1 \ --nocomp \ --crypt none \ --datashard 0 --parityshard 0 \ --sndwnd 2048 --rcvwnd 2048 \ --smuxbuf 33554432 \ --key key \ --dscp 46 \ --irtobackoff 3 --irtobthresh 128 ... 2021/03/10 16:07:46 KCP SNMP:&{BytesSent:1075839321 BytesReceived:199 MaxConn:1 ActiveOpens:0 PassiveOpens:1 CurrEstab:1 InErrs:0 InCsumErrors:0 KCPInErrors:0 InPkts:7646 OutPkts:1050351 InSegs:7654 OutSegs:1050352 InBytes:183895 OutBytes:1123856445 RetransSegs:1756 FastRetransSegs:0 EarlyRetransSegs:0 LostSegs:1756 RepeatSegs:0 FECRecovered:0 FECErrs:0 FECParityShards:0 FECShortShards:0} |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
root@B:~# client_linux_amd64_new \ --remoteaddr A:8080 \ --localaddr :33891 \ --mode manual --nodelay 0 --interval 10 --resend 0 --nc 1 \ --nocomp \ --crypt none \ --datashard 0 --parityshard 0 \ --sndwnd 2048 --rcvwnd 2048 \ --smuxbuf 33554432 \ --key key \ --dscp 46 \ --irtobackoff 3 --irtobthresh 128 ... 2021/03/10 16:07:43 KCP SNMP:&{BytesSent:191 BytesReceived:1075839313 MaxConn:1 ActiveOpens:1 PassiveOpens:0 CurrEstab:1 InErrs:0 InCsumErrors:0 KCPInErrors:0 InPkts:1050350 OutPkts:7644 InSegs:1050350 OutSegs:7652 InBytes:1102849369 OutBytes:336719 RetransSegs:0 FastRetransSegs:0 EarlyRetransSegs:0 LostSegs:0 RepeatSegs:1756 FECRecovered:0 FECErrs:0 FECParityShards:0 FECShortShards:0} |
上面的参数–irtobackoff参数原版的kcptun是没有的,只是我在自己fork的版本加进去的。–irtobackoff 3,意思就是RTO = RTO + (RTO >> 3),也就是1.125倍的RTO。如果参数改成2,也就是1.25倍的RTO,这个repeat还可以到0。具体取多少,还得测,跑的带宽更大、CPU负载更高的话,可能得应用1.5倍的RTO。
对RTO应用这个系数,会不会对传输速度产生负面影响呢?
其实一般不会有的,因为还有更准确的fast retransmit机制,它是通过segment中的ts(发送时间)与收到的ack所携带的ts进行比较判断的,而不是RTO,因此即使没到RTO,fast retransmit会在一个RTT后就立刻帮你重传,不对RTO应用这个系数的话,丢包后还很可能会fast retransmit一次,之后RTO再retransmit一次。
那交互式程序呢?例如SSH,敲键盘的速度,一般来说对方并到不了让对方在一个RTO内响应多个ack的程度,那这时岂不是要依赖RTO?前面有提到过thin stream,因此可以在KCP中引入这个机制,待发或者已发出还未被ack的segment少于某个值,就不应用这个系数,直接在一个RTO后重传。上面的参数–irtobthresh 128,就是对这个值的指定,意思就是segment少于等于128个,就在一个RTO后立刻重传。
7. 一些其它问题
7.1. 跑不满千兆
不知道有多少人拿KCP来跑那么大带宽的?之所以选用KCP,是因为一方面可以免去TCP三次握手的消耗,另一方面可以跳过慢启动,直接蹦到千兆。要知道RTT越高,这两个机制的时间成本就越高。
首先要解决前面提到的带宽利用率问题,不然跑的带宽越大,带宽利用率越低。其次,CPU要够好。目前网络设备对TCP的优化还是很足的,但是UDP比较少,例如TCP有segment和checksum offload,但是对于KCP来说,这些offload都不能用,因为NIC不认识KCP,所以只能依赖CPU处理。还有就是,KCPTUN默认给io.CopyBuffer()提供的buffer只有4KB,要跑满千兆,增大这个buffer很关键,例如调整到64K。
除此之外,别忘了调整net.core.rmem_max,至少要能容纳一个BDP的量。KCPTUN的README还提到要调整wmem的,个人在这里建议不要做调整,实测会有问题,具体调整wmem是否合适,各位自行测试。
7.2. RTT越高,速度越慢
前面提到带宽利用率是其中一个问题,此外还有segment堆积的问题,千兆带宽,snd_buf中可以堆积超过一万个segment,flush()去处理这些segment也有消耗,所以RTT越高,速度越慢,但这个影响不及带宽利用率的问题大。实测千兆,会有五十兆左右的性能损耗。
7.3. 用了后速度变慢/丢包率非常高
一般来说慢一点肯定会有的,但是如果差异太大就肯定有问题。
首先是解决带宽利用率的问题,其次,如7.1提到的,别忘了调整net.core.rmem_max。另外,窗口的设定也要合理。
如果发现丢包率非常高,而且不是在中间网络设备丢的,可能是你调大了wmem,建议将wmem_default和wmem_max都调回212992,不会影响上行性能。如果丢包还是很严重,尝试调大队列的packet limit,具体方法,请参考另一篇文章:UDP SndbufErrors & ENOBUFS。
7.4. FEC
这个适用于pps比较高的情况,其实对交互式应用来说,意义不算很大,例如你设置的FEC是10:3,你SSH敲键盘一个RTO内一般也敲不出十个字母,这种场景,回退到多倍发包比较合适。