不知道有多少人留意过,使用千兆公网带宽传输数据时,只要距离稍微远点,就无法跑满千兆。对于这种情况,可能第一反应是“线路繁忙,公网带宽不足,跑不满很正常”。不过如果你有在不同地区的多台千兆设备间传数据的经历的话,你大概会发现,最大传输速度跟延迟成负相关。
首先丢出个公式:
|
1 |
RTT * Bandwidth / 8 = BufferSize |
TCP有ARQ机制,已发出的数据要收到ACK后才能丢弃。因为至少要等一个RTT才能收到ACK,所以sendbuffer要至少能存放一个RTT内能发出的数据量。另外,TCP的拥塞控制也会根据接收方的receivebuffer大小限制数据的发出速率。因此,如果想达到100%的带宽利用率,双方的buffer size都得符合上述公式。
根据Linux kernel的document,TCP sendbuffer max size默认为4MB,所以RTT低于多少时才能保证千兆呢?
|
1 |
RTT * 1000 / 8 = 4MB |
RTT = 32ms,只要超过32ms,你的千兆带宽就不能跑满。万兆网络的话,这个数还得除以十:3.2ms,基本上只能在局域网内跑满(我猜即使buffer够了,万兆在公网还真的跑不满……)。
这里再丢出两条公式:
|
1 2 3 4 5 6 7 8 |
# sendbuffer size RTT * Bandwidth / 8 = SendBufferSize * 0.7 # receivebuffer size if net.ipv4.tcp_adv_win_scale > 0 RTT * (Bandwidth / 8) = ReceiveBufferSize - (ReceiveBufferSize / 2^net.ipv4.tcp_adv_win_scale) else RTT * (Bandwidth / 8) = ReceiveBufferSize / 2^(-net.ipv4.tcp_adv_win_scale)) |
为什么会有另外两条公式?因为开头给出的只是理论值,实际上的buffer,并非仅用来储存payload,因此需要扣除非payload部分。
sendbuffer:
第一条计算sendbuffer的公式的系数0.7,是我测出来的,并不是准确值,为什么会是接近这个值,我还在寻找答案。
receivebuffer:
计算receivebuffer的可能有点复杂,对于tcp_adv_win_scale,kernel文档解释如下:
tcp_adv_win_scale – INTEGER
Count buffering overhead as bytes/2^tcp_adv_win_scale
(if tcp_adv_win_scale > 0) or bytes-bytes/2^(-tcp_adv_win_scale),
if it is <= 0.
Possible values are [-31, 31], inclusive.
Default: 1
值的应用以及公式的出处,可以在这里找到:https://git.kernel.org/pub/scm/linux/kernel/git/stable/linux.git/tree/include/net/tcp.h?h=v5.10.12#n1395
简单来讲,就是receivebuffer有一部分是作为buffering overhead的,其大小通过tcp_adv_win_scale进行控制。所以扣除这一部分才是实际用来存放payload的size。
buffer在内核中的设定:
TCP的sendbuffer与receivebuffer分别在net.ipv4.tcp_wmem和net.ipv4.tcp_rmem中设定:
|
1 2 3 4 |
# sysctl net.ipv4.tcp_wmem net.ipv4.tcp_wmem = 4096 16384 4194304 # sysctl net.ipv4.tcp_rmem net.ipv4.tcp_rmem = 4096 131072 6291456 |
三个值分别是min,default和max,kernel会在min和max自动调整,程序也可以通过setsockopt() API设定。
下面是对buffer的调整尝试:
A到B之间的RTT是146ms,A的sendbuffer max size是默认4MB,测试下B从A下载文件的速度:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
root@B:~# ping -c A PING A 56(84) bytes of data. 64 bytes from A: icmp_seq=1 ttl=55 time=146 ms 64 bytes from A: icmp_seq=2 ttl=55 time=146 ms 64 bytes from A: icmp_seq=3 ttl=55 time=146 ms --- A ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 2002ms rtt min/avg/max/mdev = 146.868/146.877/146.890/0.009 ms root@B:~# curl -o /dev/null http://A/bigfile % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 4 5051M 4 219M 0 0 16.4M 0 0:05:07 0:00:13 0:04:54 19.0M |
调整A的sendbuffer:
|
1 2 3 4 |
root@A~:# sysctl net.ipv4.tcp_wmem net.ipv4.tcp_wmem = 4096 16384 4194304 # 0.146s * 1000Mbps / 8 / 0.7 ≈ 26M,置max为26M: sysctl -w net.ipv4.tcp_wmem="4096 16384 27262976" |
再到B上测试下速度:
|
1 2 3 4 |
root@B:~# curl -o /dev/null http://A/bigfile % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 4 5051M 4 247M 0 0 19.3M 0 0:04:20 0:00:12 0:04:08 21.2M |
快的确是快了,但只有21.2 MB/s,好像并不是预期的结果,如果你抓包看看A和B之间的数据包,你会发现,B的窗口大小上限是3 MB,见下图的Win:
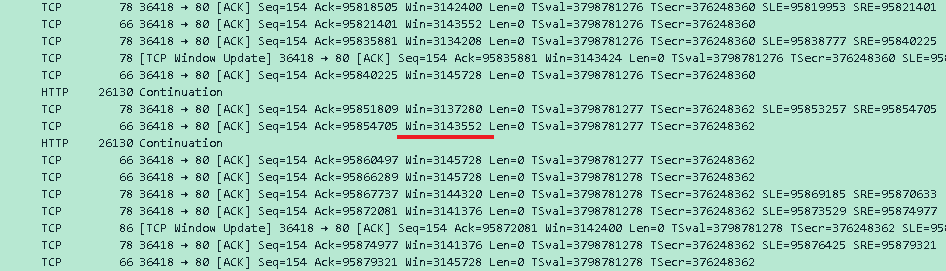
所以这限制了未被ACK的数据量,A不能发送超出B接收能力的量,通过窗口大小和RTT可以反推出速度:3MB / 0.146s ≈ 20.5MB/s,接近curl的速度。
TCP窗口大小是receivebuffer的具体表现,查看一下B的receivebuffer:
|
1 2 3 4 |
root@B:~# sysctl net.ipv4.tcp_rmem net.ipv4.tcp_rmem = 4096 131072 6291456 root@B:~# sysctl net.ipv4.tcp_adv_win_scale net.ipv4.tcp_adv_win_scale = 1 |
如果把数值代入receivebuffer的公式,你可以算得receivebuffer的值是接近6MB,跟当前tcp_rmem的max size一致,所以B目前的行为是符合这两个数值的预期的。
下面调整下B的receivebuffer:
|
1 2 3 4 5 6 7 8 9 |
# 0.146s * 1000Mbps / 8 = receivebuffer - (receivebuffer / 2^1) # 得receivebuffer = 36.5M # 置receivebuffer max size 36M root@B:~# sysctl -w net.ipv4.tcp_rmem="4096 131072 37748736" net.ipv4.tcp_rmem = 4096 131072 37748736 root@B:~# curl -o /dev/null http://A/bigfile % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 16 5051M 16 844M 0 0 92.1M 0 0:00:54 0:00:09 0:00:45 112M |
这时抓包,可以看到B的窗口大小上限是18M:

0.146s * 112MB/s = 16.352,可以确定目前的瓶颈是物理带宽而不是buffer。
再找了个与A的RTT是68ms的C:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
root@C:~# ping -c 3 A PING A 56(84) bytes of data. 64 bytes from A: icmp_seq=1 ttl=55 time=68.5 ms 64 bytes from A: icmp_seq=2 ttl=55 time=67.9 ms 64 bytes from A: icmp_seq=3 ttl=55 time=68.2 ms --- A ping statistics --- 3 packets transmitted, 3 received, 0% packet loss, time 5ms rtt min/avg/max/mdev = 67.949/68.218/68.481/0.371 ms root@C:~# curl -o /dev/null http://A/bigfile % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 15 5051M 15 782M 0 0 40.5M 0 0:02:04 0:00:19 0:01:45 45.1M |
A的sendbuffer已经调整过了,足以应付68ms的RTT,但C的receivebuffer还没调整:
|
1 2 3 4 5 6 7 8 9 10 11 |
root@C:~# sysctl net.ipv4.tcp_rmem net.ipv4.tcp_rmem = 4096 131072 6291456 root@C:~# sysctl net.ipv4.tcp_adv_win_scale net.ipv4.tcp_adv_win_scale = 1 # 调整为当前的两倍,也就是12M,那么预期的速度,按照公式,应该可以翻倍 root@C:~# sysctl -w net.ipv4.tcp_rmem="4096 131072 12582912" net.ipv4.tcp_rmem = 4096 131072 12582912 root@C:~# curl -o /dev/null http://A/bigfile % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 49 5051M 49 2519M 0 0 88.2M 0 0:00:57 0:00:28 0:00:29 91.0M |
新的速度接近原来的两倍,把数值代入公式:0.068s * rate = 12MB – (12MB / 2^1),得rate = 88.2353MB/s,接近实际速率。
另外,这里再提一个参数“tcp_slow_start_after_idle”,kernel document的解释如下:
tcp_slow_start_after_idle – BOOLEAN
If set, provide RFC2861 behavior and time out the congestion
window after an idle period. An idle period is defined at
the current RTO. If unset, the congestion window will not
be timed out after an idle period.
Default: 1
这个功能默认是启用的,连接空闲一个RTO后,后面会从新进入慢启动状态,长连接要保证稳定性能的话,置0。