前言
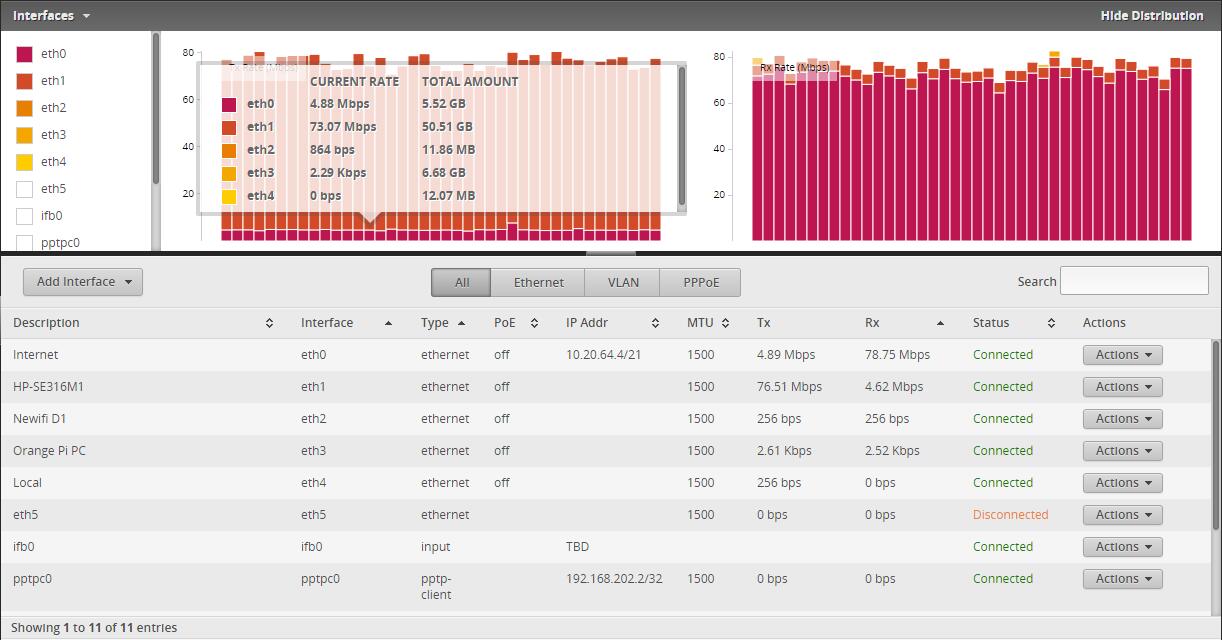
使用迅雷全速下载时,其余网络应用的体验几乎约等于断网状态。
全速下载时,迅雷并没有占用太多上行带宽,于路由器上观察上行速率,同样正常:
可见全速下载时出现的现象,问题在于下行。
迅雷全网搜索资源,这意味着会有许多来自不同地方的计算机,以高速率往我的计算机发来大量数据包。ISP处的队列早已被这些P2P数据包塞满,而SSH、网页等服务的数据包速率不高,根本不够P2P数据包竞争,这些数据包到达ISP处时,只能由于队列已满而被丢弃。
其实这个问题,并没有什么好的解决办法,因为ISP处的队列我们没有权限控制。
我们所能做的,只是控制P2P的速率,避免因ISP处队列满而使得数据包被丢弃。
不过,上行队列我们拥有完全控制权,倒可以自由规划。
蓝图
首先,我的主要目的是,当私有网络内有人使用迅雷等进行全速下载时,这个下载不会影响交互式应用、网页流量等,不受影响终端的包括下载者自己,其次,也要保证下载流的下行速率。
这是一项很有挑战性的任务。
下行流量大致可以分为三类:
- 最低延迟
- 优先传送
- 受限
这里没有普通流量这一类,因为普通流量在P2P软件,尤其是迅雷面前尤其不好区分,我尝试过Deep Packet Inspection,迅雷的流量绝大部分被分类到了Other里面。因此,与其花心思、花系统资源去区分这些“普通流量”,还不如直接使用白名单机制,把最低延迟、优先传送的区分出来。
上行流量:
- 最低延迟
- 优先传送
- 普通
- 受限
最低延迟
最低延迟的数据包,可能会以IP Header中的TOS来标记,但抓包分析发现,基本上没有使用此字段的数据包,甚至是SSH(但内网的SSH有把TOS设为0x10,表示最低延迟,可能是公网有路由清空了该字段)。所以说,只有KCPTUN之类的会“滥用”该字段,使用该字段区分最低延迟数据包意义不大。
TCP三次握手比较关键的是SYN、SYN & ACK,带有SYN和SYN & ACK标记的我们可以归类为最低延迟,此外ACK的小包(小于64字节),我们也可以归类为最低延迟。
SSH,DNS,远程桌面,QQ以及微信等交互式服务,归类为最低延迟。
优先传送
以下协议归类为优先传送:
- HTTP
- HTTPS
- SMTP
- IMAP
- GIT
这里有个问题,如果使用迅雷进行HTTP下载,迅雷也会全网搜索HTTP资源,这里正常的HTTP流量与迅雷的HTTP流量不是很好区分。
一个最大的特征是,迅雷可能会与同一个IP建立多个TCP连接,据此可把迅雷下载用的TCP连接归类到受限。
对于单连接的,这里没有好的办法,有以下几个原因:
根据速率区分:前面已提到迅雷会全网搜索资源,意味着迅雷会构建很多TCP连接,单个TCP连接的速率不会很高。阈值低了,影响正常网页流量,高了,无效。
根据传输流量区分:首先HTTP 1.1支持Keep Alive,这意味着对于正常网页的TCP连接来说,流量达到阈值也是有可能的。
上述二者结合:如果我一个网站同时打开多几个页面,岂不是一样被归类为受限?况且现在一个页面数MB,也很正常吧?
根据内网IP构建的TCP连接数区分:我的目的是不要让迅雷影响正常的应用,如果让某个TCP连接数多的IP归类到受限,岂不是不能实现我这个目的?
普通
本分类仅用于上行,未被归类的均归于普通类。
受限
对于下行,未被归类的,均为受限。
P2P的上行发送的都是大于1350字节的UDP数据包,把这些数据包归类为受限即可。
实现
我使用的是中国电信的带宽
下行:100 Mbps,上行:20 Mbps。
互联网接口:eth0,私有网络接口:switch0。
首先设置以下数个变量,方便后面的命令使用:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
internetDev="eth0" # 互联网接口 privateNetDev="switch0" # 私有网络接口 uploadRate="20mbit" # 互联网上行带宽 uploadP2PRate="1mbit" # P2P上行带宽 uploadEmerRate=${uploadRate} # 最低延迟上行带宽 uploadPrioRate=${uploadRate} # 优先传送上行带宽 uploadNormalRate="10mbit" # 普通流量上行带宽 downloadRate="100mbit" # 互联网下行带宽 downloadP2PRate="80mbit" # P2P下行带宽 downloadEmerRate=${downloadRate} # 最低延迟传送下行带宽 downloadPrioRate=${downloadRate} # 优先传送下行带宽 |
这里我主要的目的在于不要让P2P把ISP处的队列占满,其次对于正常的流量,并不会占用太多带宽,因此正常流量不作速率限制,仅分配不同的优先级,而P2P则限制速率,设置最低的优先级。
区分P2P上行
把大于1350字节的UDP数据包,都标记为100。
|
1 2 3 4 |
# For QoS, MARK 100 iptables -t mangle -N MARK_100 iptables -t mangle -A MARK_100 -p udp -m length ! --length 0:1350 -j MARK --set-mark 100 iptables -t mangle -I PREROUTING -i ${privateNetDev} -j MARK_100 |
区分迅雷TCP流
P2P的不需要区分,因为下行使用的是白名单机制。
主要问题在于迅雷的HTTP下载,实难区分,这里用了一个不太尽人意的方法,把迅雷的TCP流标记为200:
|
1 2 3 4 5 6 7 |
# For QoS, MARK 200 iptables -t mangle -N PRIVATE_NET_MARK_200 iptables -t mangle -A PRIVATE_NET_MARK_200 -p tcp -j CONNMARK --restore-mark iptables -t mangle -A PRIVATE_NET_MARK_200 -m mark --mark 200 -j RETURN iptables -t mangle -A PRIVATE_NET_MARK_200 -m connlimit --connlimit-above 4 --connlimit-mask 24 --connlimit-saddr -m hashlimit --hashlimit-above 512kb/second --hashlimit-burst 5mb --hashlimit-mode srcip,dstip --hashlimit-dstmask 24 --hashlimit-srcmask 32 --hashlimit-name rateLimit -j MARK --set-mark 200 iptables -t mangle -A PRIVATE_NET_MARK_200 -j CONNMARK --save-mark iptables -t mangle -I POSTROUTING -o ${privateNetDev} -j PRIVATE_NET_MARK_200 |
首先,不能在互联网接口上对TCP流进行归类,因为在互联网接口上,所有TCP流的目的地都是我们互联网接口的IP,这导致的问题就是无法独立统计单个内网IP对单个远程IP的链接数。想一想,如果网内有多个人同时访问某个网站,是不是有可能被归类为受限?
因此这里在私有网络的接口上进行归类。
归类用到了两个模块,分别是connlimit,hashlimit。
connlimit模块仅能统计单端的链接数,hashlimit模块能双端统计,但是只能统计速率,因此配合使用,以接近限制端对端链接数的效果。
这里connlimit用到的参数,表示远程一个/24与本地构建的TCP流超过四的情况;hashlimit的参数表示远程一个/24与本地一个IP突发5MB后,数据传输速率>512kb/s的情况。
这里还用到了connmark模块,这个模块用于记录TCP流的标记,下次遇到相同的TCP流时,取上次的标记即可,无需再使用connlimit与hashlimit模块进行判断,因为这两个模块资源消耗不低。
构建上行规则
这里使用了HTB对速率进行限制,并在每个类下面安置了一个SFQ队列,以公平分配一个队列中各流的带宽:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
tc qdisc del dev ${internetDev} root # 删除现有的规则 tc qdisc add dev ${internetDev} root handle 1: htb default 50 # 默认归类到类50 tc class add dev ${internetDev} parent 1: classid 1:1 htb rate ${uploadRate} tc class add dev ${internetDev} parent 1:1 classid 1:100 htb rate ${uploadP2PRate} ceil ${uploadP2PRate} prio 7 # P2P 优先级7 tc class add dev ${internetDev} parent 1:1 classid 1:10 htb rate ${uploadEmerRate} prio 0 # 最低延迟 优先级0 tc class add dev ${internetDev} parent 1:1 classid 1:20 htb rate ${uploadPrioRate} prio 2 # 优先传送 优先级2 tc class add dev ${internetDev} parent 1:1 classid 1:50 htb rate ${uploadNormalRate} prio 5 # 普通 优先级5 # 随机公平队列 tc qdisc add dev ${internetDev} parent 1:100 handle 100: sfq perturb 10 tc qdisc add dev ${internetDev} parent 1:10 handle 10: sfq perturb 10 tc qdisc add dev ${internetDev} parent 1:20 handle 20: sfq perturb 10 tc qdisc add dev ${internetDev} parent 1:50 handle 50: sfq perturb 10 |
接下来就把数据包归类,我选择使用u32选择器。
u32选择器强大,同时也难用。
u8, u16都会转换为u32,uX跟着一个值与掩码,at后面是偏移量,偏移从IP Header开始。
掩码将会与数据包偏移位置处进行位于,再与给定的值进行比较。
更多u32选择器的细节,见u32选择器的手册页:Universal 32bit classifier in tc(8) LinuxUniversal 32bit classifier in tc(8)
分类规则:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 |
# Match TCP SYN tc filter add dev ${internetDev} protocol ip parent 1:0 pref 1 u32 \ match u8 0x10 0xff at 33 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP ACK Small Packet (< 64 Bytes) tc filter add dev ${internetDev} protocol ip parent 1:0 pref 1 u32 \ match u8 0x10 0xff at 33 \ match u8 0x06 0xff at 9 \ match u16 0x0000 0xffc0 at 2 \ flowid 1:10 # Match TCP DESTINATION PORT 22 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0016 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP DESTINATION PORT 23 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0017 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP DESTINATION PORT 25 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0019 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP DESTINATION PORT 53 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0035 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match UDP DESTINATION PORT 53 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0035 0xffff at 22 \ match u8 0x11 0xff at 9 \ flowid 1:10 # Match TCP DESTINATION PORT 80 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0050 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP DESTINATION PORT 443 tc filter add dev ${internetDev} protocol ip parent 1: pref 10 u32 \ match u16 0x01bb 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match UDP DESTINATION PORT 443 (QUIC Protocol) tc filter add dev ${internetDev} protocol ip parent 1: pref 10 u32 \ match u16 0x01bb 0xffff at 22 \ match u8 0x11 0xff at 9 \ flowid 1:20 # Match TCP DESTINATION PORT 465 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x01d1 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP DESTINATION PORT 993 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x03e1 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP DESTINATION PORT 3306 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0cea 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP DESTINATION PORT 3389 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0d3d 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match UDP DESTINATION PORT 3389 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0d3d 0xffff at 22 \ match u8 0x11 0xff at 9 \ flowid 1:10 # Match UDP DESTINATION PORT 8000 (QQ Port) tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x1f40 0xffff at 22 \ match u8 0x11 0xff at 9 \ flowid 1:10 # Match TCP DESTINATION PORT 8080 (WeChat Port) tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x1f90 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP DESTINATION PORT 9418 (GIT) tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x24ca 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Limit UDP Huge Packet Rate tc filter add dev ${internetDev} protocol ip parent 1:0 pref 20 u32 \ match mark 0x0064 0x00ff \ flowid 1:100 |
构建下行规则
队列的构建与上面同理,只是少了一个普通流量的类:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
tc qdisc del dev ${privateNetDev} root # 删除现有的队列 tc qdisc add dev ${privateNetDev} root handle 1: htb default 100 # 默认归类到100 tc class add dev ${privateNetDev} parent 1: classid 1:1 htb rate ${downloadRate} tc class add dev ${privateNetDev} parent 1:1 classid 1:100 htb rate ${downloadP2PRate} ceil ${downloadP2PRate} prio 7 # P2P tc class add dev ${privateNetDev} parent 1:1 classid 1:10 htb rate ${downloadEmerRate} prio 0 # 最低延迟 tc class add dev ${privateNetDev} parent 1:1 classid 1:20 htb rate ${downloadPrioRate} prio 2 # 优先传送 # 随机公平队列 tc qdisc add dev ${privateNetDev} parent 1:100 handle 100: sfq perturb 10 tc qdisc add dev ${privateNetDev} parent 1:10 handle 10: sfq perturb 10 tc qdisc add dev ${privateNetDev} parent 1:20 handle 20: sfq perturb 10 |
归类:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 |
# Match TCP SYN ACK tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 1 u32 \ match u8 0x12 0xff at 33 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP ACK Small Packet (< 64 Bytes) tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 1 u32 \ match u8 0x10 0xff at 33 \ match u8 0x06 0xff at 9 \ match u16 0x0000 0xffc0 at 2 \ flowid 1:10 # Match multip thread download tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 5 u32 \ match mark 0x00c8 0x00ff \ flowid 1:100 # Match TCP SOURCE PORT 22 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0016 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP SOURCE PORT 23 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0017 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP SOURCE PORT 25 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0019 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP SOURCE PORT 53 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0035 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match UDP SOURCE PORT 53 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0035 0xffff at 20 \ match u8 0x11 0xff at 9 \ flowid 1:10 # Match TCP SOURCE PORT 80 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0050 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP SOURCE PORT 443 tc filter add dev ${privateNetDev} protocol ip parent 1: pref 10 u32 \ match u16 0x01bb 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match UDP SOURCE PORT 443 (QUIC Protocol) tc filter add dev ${privateNetDev} protocol ip parent 1: pref 10 u32 \ match u16 0x01bb 0xffff at 20 \ match u8 0x11 0xff at 9 \ flowid 1:20 # Match TCP SOURCE PORT 465 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x01d1 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP SOURCE PORT 993 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x03e1 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP SOURCE PORT 3306 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0cea 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP SOURCE PORT 3389 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0d3d 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match UDP SOURCE PORT 3389 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0d3d 0xffff at 20 \ match u8 0x11 0xff at 9 \ flowid 1:10 # Match UDP SOURCE PORT 8000 (QQ Port) tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x1f40 0xffff at 20 \ match u8 0x11 0xff at 9 \ flowid 1:10 # Match TCP SOURCE PORT 8080 (WeChat Port) tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x1f90 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP SOURCE PORT 9418 (GIT) tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x24ca 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 |
完整的Script
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 |
#!/bin/bash internetDev="eth0" # 互联网接口 privateNetDev="switch0" # 私有网络接口 uploadRate="20mbit" # 互联网上行带宽 uploadP2PRate="1mbit" # P2P上行带宽 uploadEmerRate=${uploadRate} # 最低延迟上行带宽 uploadPrioRate=${uploadRate} # 优先传送上行带宽 uploadNormalRate="10mbit" # 普通流量上行带宽 downloadRate="100mbit" # 互联网下行带宽 downloadP2PRate="80mbit" # P2P下行带宽 downloadEmerRate=${downloadRate} # 最低延迟传送下行带宽 downloadPrioRate=${downloadRate} # 优先传送下行带宽 # For QoS, MARK 100 iptables -t mangle -F MARK_100 > /dev/null 2>&1 iptables -t mangle -N MARK_100 > /dev/null 2>&1 iptables -t mangle -A MARK_100 -p udp -m length ! --length 0:1350 -j MARK --set-mark 100 while iptables -t mangle -D PREROUTING -i ${privateNetDev} -j MARK_100 >/dev/null 2>&1; do continue; done iptables -t mangle -I PREROUTING -i ${privateNetDev} -j MARK_100 tc qdisc del dev ${internetDev} root >/dev/null 2>&1 tc qdisc add dev ${internetDev} root handle 1: htb default 50 tc class add dev ${internetDev} parent 1: classid 1:1 htb rate ${uploadRate} tc class add dev ${internetDev} parent 1:1 classid 1:100 htb rate ${uploadP2PRate} ceil ${uploadP2PRate} prio 7 tc class add dev ${internetDev} parent 1:1 classid 1:10 htb rate ${uploadEmerRate} prio 0 tc class add dev ${internetDev} parent 1:1 classid 1:20 htb rate ${uploadPrioRate} prio 2 tc class add dev ${internetDev} parent 1:1 classid 1:50 htb rate ${uploadNormalRate} prio 5 tc qdisc add dev ${internetDev} parent 1:100 handle 100: sfq perturb 10 tc qdisc add dev ${internetDev} parent 1:10 handle 10: sfq perturb 10 tc qdisc add dev ${internetDev} parent 1:20 handle 20: sfq perturb 10 tc qdisc add dev ${internetDev} parent 1:50 handle 50: sfq perturb 10 # Match TCP SYN tc filter add dev ${internetDev} protocol ip parent 1:0 pref 1 u32 \ match u8 0x10 0xff at 33 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP ACK Small Packet (< 64 Bytes) tc filter add dev ${internetDev} protocol ip parent 1:0 pref 1 u32 \ match u8 0x10 0xff at 33 \ match u8 0x06 0xff at 9 \ match u16 0x0000 0xffc0 at 2 \ flowid 1:10 # Match TCP DESTINATION PORT 22 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0016 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP DESTINATION PORT 23 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0017 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP DESTINATION PORT 25 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0019 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP DESTINATION PORT 53 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0035 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match UDP DESTINATION PORT 53 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0035 0xffff at 22 \ match u8 0x11 0xff at 9 \ flowid 1:10 # Match TCP DESTINATION PORT 80 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0050 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP DESTINATION PORT 443 tc filter add dev ${internetDev} protocol ip parent 1: pref 10 u32 \ match u16 0x01bb 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match UDP DESTINATION PORT 443 (QUIC Protocol) tc filter add dev ${internetDev} protocol ip parent 1: pref 10 u32 \ match u16 0x01bb 0xffff at 22 \ match u8 0x11 0xff at 9 \ flowid 1:20 # Match TCP DESTINATION PORT 465 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x01d1 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP DESTINATION PORT 993 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x03e1 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP DESTINATION PORT 3306 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0cea 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP DESTINATION PORT 3389 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0d3d 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match UDP DESTINATION PORT 3389 tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0d3d 0xffff at 22 \ match u8 0x11 0xff at 9 \ flowid 1:10 # Match UDP DESTINATION PORT 8000 (QQ Port) tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x1f40 0xffff at 22 \ match u8 0x11 0xff at 9 \ flowid 1:10 # Match TCP DESTINATION PORT 8080 (WeChat Port) tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x1f90 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP DESTINATION PORT 9418 (GIT) tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x24ca 0xffff at 22 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Limit UDP Huge Packet Rate tc filter add dev ${internetDev} protocol ip parent 1:0 pref 20 u32 \ match mark 0x0064 0x00ff \ flowid 1:100 # For QoS, MARK 200 iptables -t mangle -F PRIVATE_NET_MARK_200 >/dev/null 2>&1 iptables -t mangle -N PRIVATE_NET_MARK_200 >/dev/null 2>&1 iptables -t mangle -A PRIVATE_NET_MARK_200 -p tcp -j CONNMARK --restore-mark iptables -t mangle -A PRIVATE_NET_MARK_200 -m mark --mark 200 -j RETURN iptables -t mangle -A PRIVATE_NET_MARK_200 -m connlimit --connlimit-above 4 --connlimit-mask 24 --connlimit-saddr -m hashlimit --hashlimit-above 512kb/second --hashlimit-burst 5mb --hashlimit-mode srcip,dstip --hashlimit-dstmask 24 --hashlimit-srcmask 32 --hashlimit-name packetRateLimit -j MARK --set-mark 200 iptables -t mangle -A PRIVATE_NET_MARK_200 -j CONNMARK --save-mark while iptables -t mangle -D POSTROUTING -o ${privateNetDev} -j PRIVATE_NET_MARK_200 >/dev/null 2>&1; do continue; done iptables -t mangle -I POSTROUTING -o ${privateNetDev} -j PRIVATE_NET_MARK_200 tc qdisc del dev ${privateNetDev} root >/dev/null 2>&1 tc qdisc add dev ${privateNetDev} root handle 1: htb default 100 tc class add dev ${privateNetDev} parent 1: classid 1:1 htb rate ${downloadRate} tc class add dev ${privateNetDev} parent 1:1 classid 1:100 htb rate ${downloadP2PRate} ceil ${downloadP2PRate} prio 7 tc class add dev ${privateNetDev} parent 1:1 classid 1:10 htb rate ${downloadEmerRate} prio 0 tc class add dev ${privateNetDev} parent 1:1 classid 1:20 htb rate ${downloadPrioRate} prio 2 tc qdisc add dev ${privateNetDev} parent 1:100 handle 100: sfq perturb 10 tc qdisc add dev ${privateNetDev} parent 1:10 handle 10: sfq perturb 10 tc qdisc add dev ${privateNetDev} parent 1:20 handle 20: sfq perturb 10 # Match TCP SYN ACK tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 1 u32 \ match u8 0x12 0xff at 33 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP ACK Small Packet (< 64 Bytes) tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 1 u32 \ match u8 0x10 0xff at 33 \ match u8 0x06 0xff at 9 \ match u16 0x0000 0xffc0 at 2 \ flowid 1:10 # Match multip thread download tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 5 u32 \ match mark 0x00c8 0x00ff \ flowid 1:100 # Match TCP SOURCE PORT 22 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0016 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP SOURCE PORT 23 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0017 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP SOURCE PORT 25 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0019 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP SOURCE PORT 53 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0035 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match UDP SOURCE PORT 53 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0035 0xffff at 20 \ match u8 0x11 0xff at 9 \ flowid 1:10 # Match TCP SOURCE PORT 80 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0050 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP SOURCE PORT 443 tc filter add dev ${privateNetDev} protocol ip parent 1: pref 10 u32 \ match u16 0x01bb 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match UDP SOURCE PORT 443 (QUIC Protocol) tc filter add dev ${privateNetDev} protocol ip parent 1: pref 10 u32 \ match u16 0x01bb 0xffff at 20 \ match u8 0x11 0xff at 9 \ flowid 1:20 # Match TCP SOURCE PORT 465 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x01d1 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP SOURCE PORT 993 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x03e1 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP SOURCE PORT 3306 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0cea 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 # Match TCP SOURCE PORT 3389 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0d3d 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match UDP SOURCE PORT 3389 tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x0d3d 0xffff at 20 \ match u8 0x11 0xff at 9 \ flowid 1:10 # Match UDP SOURCE PORT 8000 (QQ Port) tc filter add dev ${internetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x1f40 0xffff at 20 \ match u8 0x11 0xff at 9 \ flowid 1:10 # Match TCP SOURCE PORT 8080 (WeChat Port) tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x1f90 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:10 # Match TCP SOURCE PORT 9418 (GIT) tc filter add dev ${privateNetDev} protocol ip parent 1:0 pref 10 u32 \ match u16 0x24ca 0xffff at 20 \ match u8 0x06 0xff at 9 \ flowid 1:20 |
总结
对P2P的归类效果还是非常好的:
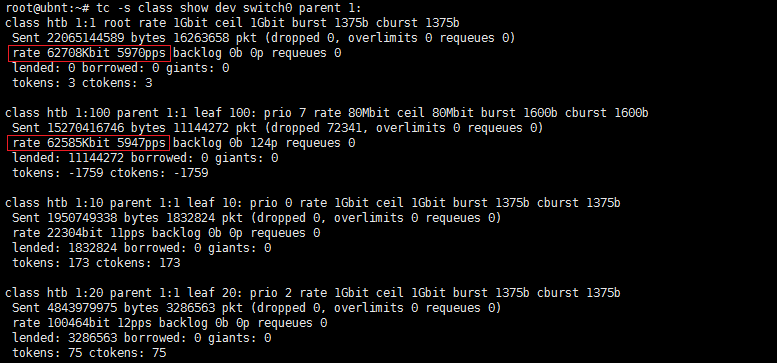
1:1是总的下行,1:100是P2P的类别的下行。
P2P上行也很精确地限制在了1 Mbps:
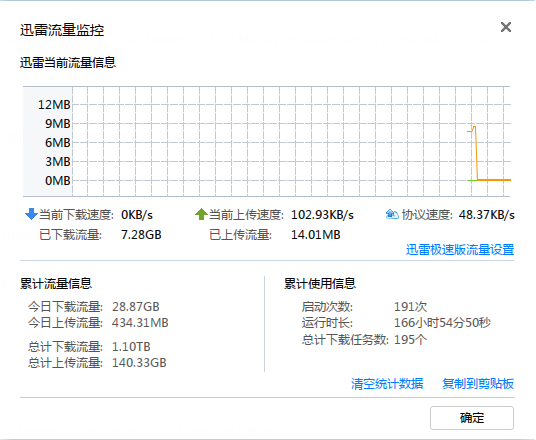
要对迅雷的全网HTTP资源多线程下载完全正确归类可能做不到,但IP对IP流量大,高数据包速率的都能受限,正常的网页流量,交互式应用受到的影响不会太大。
下行速率的控制会不太准确,毕竟我们无法控制远程计算机给我们发包的速率,需要根据实际情况适当减少rate的值。
对于延迟,就比较难保证了,这依赖于ISP的队列规则,即使我们尽量做到不让ISP处丢包,但大量的数据包排队还是会导致其余应用的延迟增加。我这里把P2P的下行速率限制为80 Mbps,P2P全速下载时,延迟也只是增加了5 – 10 ms,可以接受,ISP处的队列比较合理。